 là gì? (Phần 1)")
Dạo gần đây có một khái niệm đang nổi lên và được nhắc đến nhiều, nghe quen quen nhưng lại lạ lạ, đó chính là ELT.
ELT là gì? ELT có phải là ETL ( Extract Transform Load ) mà viết nhầm không? Hoàn toàn không nhé. ELT là một khái niệm hoàn toàn độc lập với ETL và bộ công cụ để triển khai nó cũng không tương đồng với ETL. Tuy nhiên, dù là ETL hay ELT thì chúng đều là các quá trình xử lí dữ liệu với mục đích để load dữ liệu vào DW. Cho nên để hiểu rõ ELT trước tiên bạn có thể tham khảo thêm ETL là gì (nếu bạn chưa biết) tại đây:
Mình sẽ nhắc lại sơ sơ quá trình ETL trong bài viết này bằng chart dưới đây.
Table of Contents
ETL
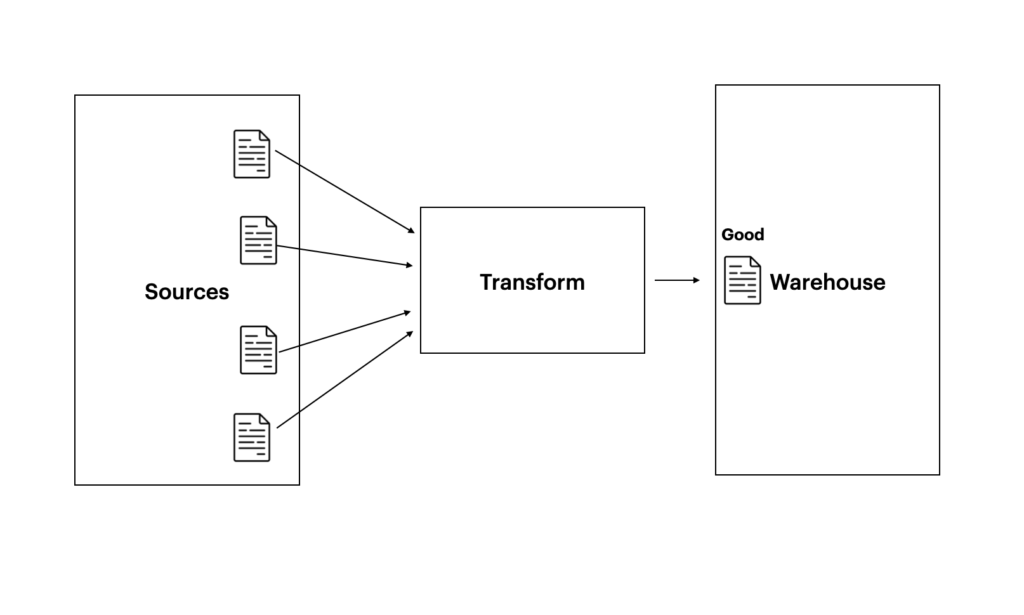
Trong ETL có 3 thành phần, đầu tiên là nguồn dữ liệu (sources) , thứ 2 là bộ phận transform ( nó có thể là 1 phần mềm được setup chạy ở đâu đó) có kết nối trực tiếp với sources và cuối cùng là 1 nơi dùng để lưu data có thể gọi là data ware house.
Được gọi là ETL bởi vì, bộ phận transform này sẽ load dữ liệu từ nguồn vào và lưu trong bộ nhớ của nó, sau đó trực tiếp thực hiện tính toán và trả dữ liệu đã được tính toán về đầu cuối là data warehouse.
Như vậy toàn bộ Business Logic lúc này sẽ tập trung trên bộ phận transform này. Tức là phải lấy data và tính toán từ nguồn như thế nào. Ví dụ như bạn lấy data số liệu bán bún của cửa hàng từ nguồn, nhưng bạn chỉ muốn tính doanh thu của bán bún ốc, còn bán ngan thì không tính. Vậy thông tin để lọc chỉ bún ốc sẽ được lưu và thực hiện trên transform.
Ngoài ra, thường thì data warehouse cũng sẽ có khả năng tính toán riêng ( thường thì là DW đều hỗ trợ SQL ) do đó trong ETL, chúng ta sẽ thấy cả DW và bộ phận transform đều có thể biến đổi dữ liệu.
Một số vấn đề với ETL (Mà mình có thể nghĩ ngay ra tại đây)
Phân tán business logic
Do có 2 bộ phận computation cùng 1 lúc, cho nên business logic cũng dễ dàng bị lưu trữ tại 2 nơi. Ví dụ như bạn là Data Analyst và dùng dữ liệu đầu cuối của bún ốc ở ví dụ trên, mà bạn chỉ quan tâm bún ngan loại đặc biệt thôi. Như vậy dữ liệu đã trãi qua 2 lần filter 1 lần trên layer transform, và 1 lần trên Data warehouse. Do business logic bị phân mảnh ra 2 nơi nên nguồn gốc (Data lineage) cũng trở nên khó truy vết hơn (trace)
Quản lý nhiều hệ thống
2 bộ phận computation cùng lúc cũng đồng nghĩa với 2 thứ để quản lý cho data engineers. Bởi vì nếu bộ phận transform chết thì sẽ không có data cho DW, mà nếu bộ phận DW chết thì lại không có nơi cho analyst query dữ liệu thì transform cũng vô dụng.
Cần 2 nhóm nhân sự để vận hành
DW thường là SQL, còn transform thì có thể là SQL hoặc là ngôn ngữ khác như Python, Scala,… Business logic đã ở nhiều nơi còn bị viết trên nhiều ngôn ngữ khác nhau.
Tốn kém
Này thì rõ ràng rồi, nhìn các điểm trên là biết
Sau khi đã biết được ETL và một số nhược điểm, chúng ta hãy xem xét ELT
ELT
ELT đơn giản là Extract Load Transform, nghịch đảo lại 2 bước cuối. Làm sao có thể làm được điều này? Chúng ta hãy check hình minh họa dưới đây nhé.
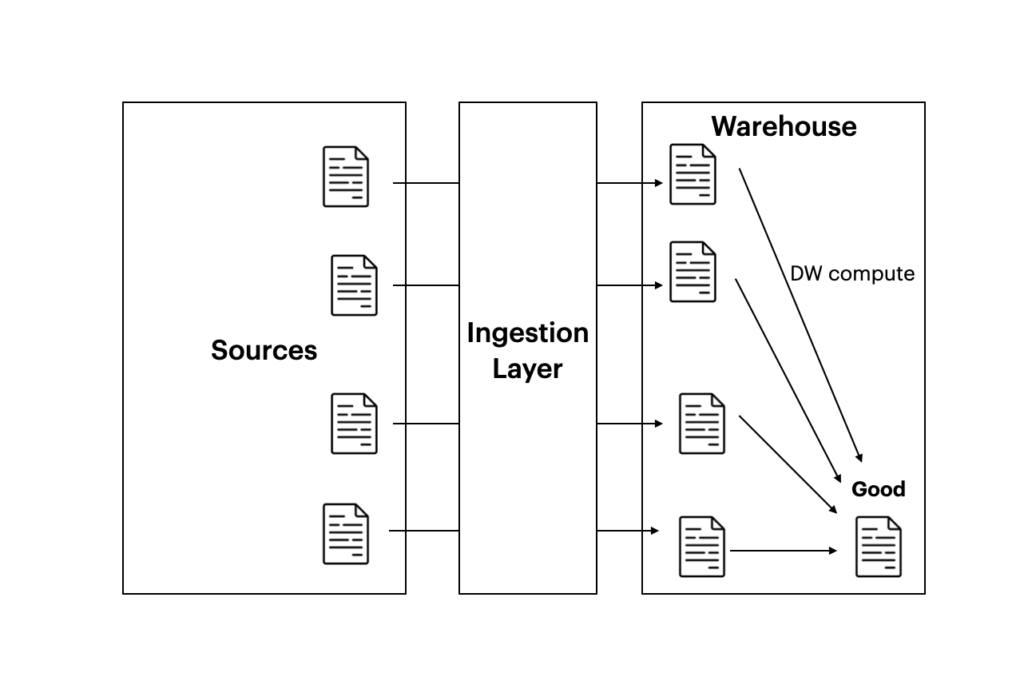
Data từ nguồn sẽ được nhân bản vào Data Warehouse, sau đó chúng ta sẽ mượn khả năng tính toán của các DataWarehouse hiện đại (như Redshift, BigQuery, Snowflake,… ) để trực tiếp tính toán trên các dữ liệu này và transform nó ngay trong warehouse chứ không thông qua một bước đệm nào.
Dễ nhận thấy có một thành phần mới trong hình được gọi là Ingestion layer, vậy thì cục ingestion layer này nó khác gì transform ? Mình sẽ giải thích phía bên dưới khi bàn tính ưu việt của mô hình này.
Tính ưu việt của ELT
Business logic tập trung về một mối
Business logic tập trung ở Data Warehouse, bạn transform gì, query gì, filter gì đều nằm trên warehouse hết, không cần phải đi ra ngoài warehouse. Điều này thành hiện thực bởi vì ở ingestion layer, chúng ta chỉ quan tâm đến việc load dữ liệu vào DW chứ không có business logic ở ingestion layer Load tất cả dữ liệu vào DW rồi business logic mới bắt đầu.
Quản lý ít hệ thống hơn
“Ơ, sao lại ít hơn có ông ingestion layer kia mà?”
Bạn hãy bình tĩnh, vì ông ingestion layer này không chứa business logic, ngoài ra còn có rất nhiều dịch vụ SaaS hoặc công cụ open source cho ingestion layer cho nên thực ra ingestion layer dễ quản lí hơn transform layer rất nhiều ( có khi 1/10 effort ).
Ở transform layer trước đây thì nếu mà muốn tiết kiệm hoặc có những thứ như spark cluster, việc quản lí chúng thôi đã tốn rất nhiều năng lượng của một data team. Còn đối với ingestion layer, nếu bạn dùng SaaS như FiveTran, Airbyte Cloud,…. hay open source như AirByte công việc quản lí thường là chỉ chọn data để load về, và update nếu có cập nhật (cho open source).
Không cần nhân sự cho lớp transform ( hoặc cần ít hơn nhiều )
Bởi vì transform xảy ra trong data warehouse, bạn hoàn toàn có thể training team hiện tại như data analysts , BA ,.. vân vân mây mây… biết viết SQL là được. Khi code SQL đạt đủ 1 tiêu chuẩn đề ra bạn có thể sử dụng các công cụ như DBT để thực hiện CI/CD và làm cho DW của bạn có transformation tốt không khác gì có transformation layer. Tất cả đều trên 1 codebase được viết bởi SQL dialect của loại data warehouse bạn đang sử dụng.
Rẻ hơn trong đa số trường hợp
Vì ingestion layer thường không có maintaining cost quá cao, và phí dịch vụ (nếu saas) cũng thấp hơn transform layer, cho nên chúng ta có thể tiết kiệm ngay được khoản phí dịch vụ.
Ngoài ra vì không cần người quản lí transform layer nữa nên cũng cắt được nhân sự cho khoảng này.
Vì transform xảy ra trong DW nên có thể sử dụng luôn cả nguồn lực sẵn có của công ty để triển khai data transformation, chứ không cần thuê người giỏi những công cụ transform cụ thể như Spark, Beam,…
Kết
Vậy là mình đã giới thiệu cho các bạn khái niệm ELT và các điểm ưu việt của nó hơn ETL rồi đó. Tất nhiên ELT cũng có các điểm trừ nữa, nhưng đây là bài post để tung hô ELT nên mình chỉ liệt kê điểm tốt của nó thôi ( mình lười viết nữa lắm ). Các bạn hãy đón đọc kì sau mình sẽ viết thêm về các công cụ để triển khai ELT nhé.