")
Update: 27-03-2023.
Stable diffusion là một model được open-source gần đây bởi một công ty tên là Stability AI, điểm đặc biệt của stable diffusion đó chính là khả năng tạo ra generative art rất chân thực ( nếu có prompt chuẩn có thể không phân biệt được với họa sĩ vẽ).
Do hiện tại tốc độ thay đổi của Stable Diffusion rất nhanh, có quá nhiều tài nguyên và bài báo, bài viết liên quan nên mình không muốn viết một bài viết hướng dẫn các bạn chi tiết cách sử dụng hay dùng một thư viện cụ thể nào. Trong bài viết sau đây, mình chỉ muốn đưa các bạn tới các đường link hữu ích giúp các bạn có thể tự tìm hiểu cách sử dụng stable diffusion, hoặc học các chủ đề liên quan tới stable diffusion.
Mình sẽ phân loại các trang web, đường link theo mục đích và đính kèm hướng dẫn theo bài viết.
Table of Contents
Công cụ thường dùng
Các công cụ để tạo ảnh (inference)
WEB
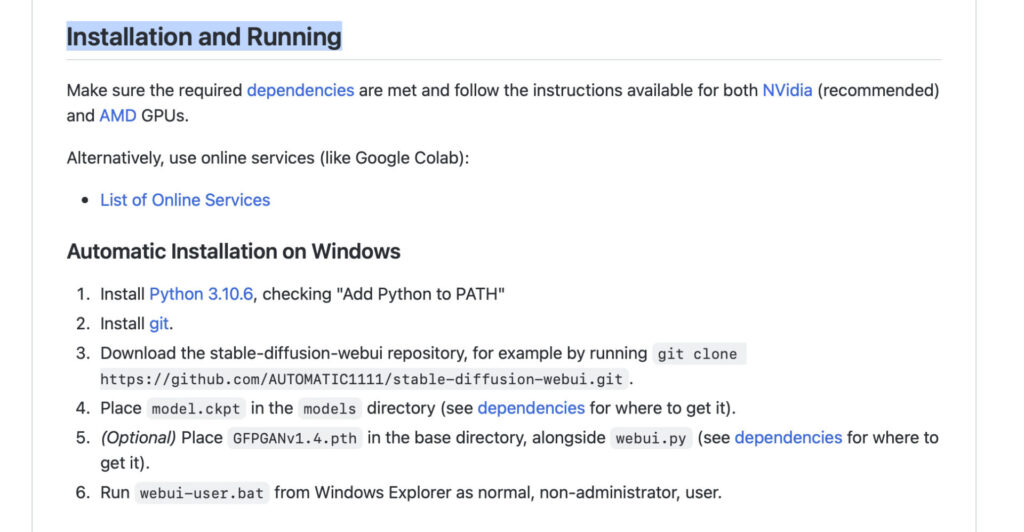
Automatic1111 Web UI
Automatic là công cụ để tương tác với Stable Diffusion bằng UI có lượng người dùng đông đảo nhất, update nhanh nhất (luôn luôn có đủ và rất nhiều features, có những features thậm chí còn được implement và được sử dụng rất nhiều mặc dù không có trong implementation gốc)
Các bạn có thể tải và cài đặt tại link dưới đây. Tuỳ vào cấu hình và máy của bạn sẽ có nhiều hướng dẫn khác nhau, hãy check tại mục installation nhé.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
Invoke-AI
Đây là công cụ phổ biến thứ 2 chỉ xếp sau automatic1111, điểm mạnh của Invoke-AI chính là có UI rất đẹp hiện tại là đẹp nhất so với các công cụ khác. Invoke-AI rất mạnh trong khoảng Inpainting và Outpaining (mình sẽ giải thích ở phía sau các keywords này là gì).

Link: https://github.com/invoke-ai/InvokeAI
IOS – MACOS
draw things: AI GENERATION (Update)
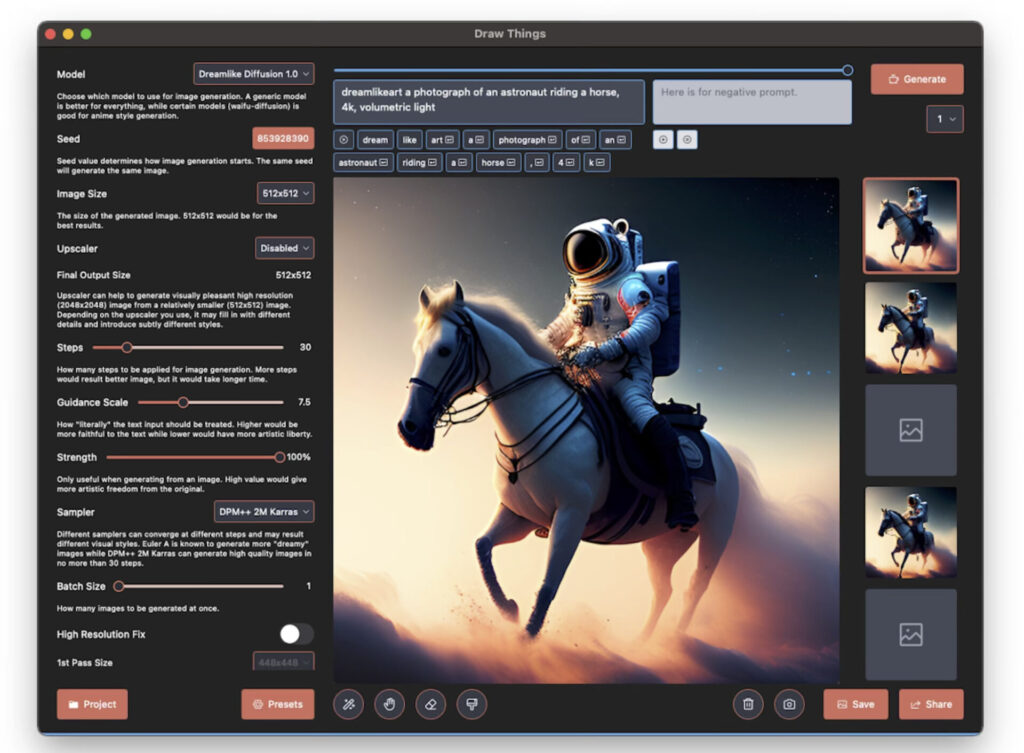
Draw things là tool để chạy model stable diffusion được tối ưu cho IOS, thậm chí có thể chạy được trên iPhone. Mặc dù không có nhiều tính năng như automatic nhưng nó lại rất dễ sử dụng.
Link: https://apps.apple.com/vn/app/draw-things-ai-generation/id6444050820
Các công cụ để tạo ảnh online (Miễn phí)
Mình nhận thấy là không phải bạn nào cũng có điều kiện để dùng máy có cấu hình tốt để chạy đua với các yêu cầu ngày càng cao của Stable Diffusion hiện tại cho nên mình quyết định bổ sung thêm phần các công cụ tạo ảnh miễn phí.
StableHorde
Stable Horde là trang web giúp bạn chạy Stable Diffusion “hoàn toàn miễn phí”. Đây là trang web dành cho những người có máy chạy tốt được stable diffusion tham gia để tình nguyện cho bạn tạo ảnh trên máy của họ. Trang web này được lập ra nhằm mục đích nghiên cứu.
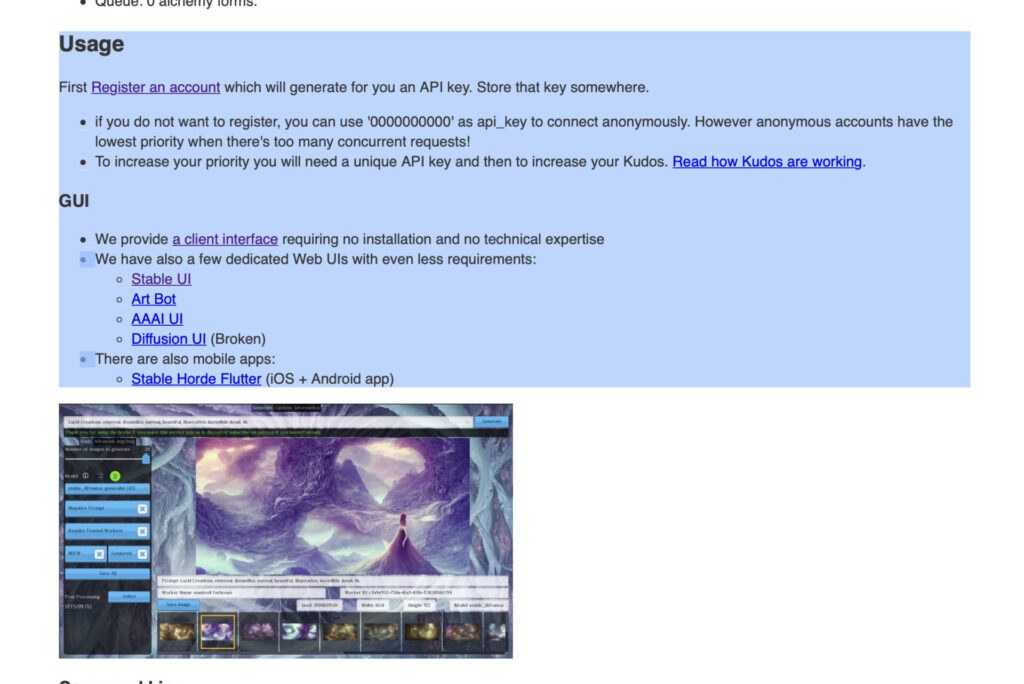
Tất cả những gì bạn cần làm là vào trang web này https://stablehorde.net để đăng ký tài khoản. Sau khi bạn đăng ký tài khoản stable horde sẽ cho bạn một API key. Khi bạn có API key hãy vào lại trang chủ và kéo xuống phần “Usage” để xem hướng dẫn cách sử dụng Stable Horde nhé.
Mage Space

Mage Space là một trang web dịch vụ cho bạn tạo ảnh từ Stable Diffusion, họ đã set up hết Stable Diffusion rồi, các bạn chỉ việc tạo ảnh thôi. Mage Space được mình thêm vào vì lí do họ có cho sử dụng miễn phí các tính năng cơ bản. Nếu bạn không có nhu cầu cao mà chỉ muốn thử qua Stable Diffusion, thì bạn hoàn toàn có thể thử bằng việc sử dụng Mage Space nhé.
Các bạn tạo ảnh tại trang web này nhé: https://mage.space
Các trang web có nhiều models
Stable Diffusion chỉ là một phiên bản gốc, trong thực tế mọi người dùng rất nhiều model khác nhau đã được fine-tuned lại, có rất nhiều style và cải tiến so với Stable Diffusion. Các bạn có thể xem các ảnh mình đã vẽ bằng AI dưới đây làm mẫu.









Tất cả những hình ảnh phía trên đều không phải là Stable Diffusion gốc mà là phiên bản đã được fine-tuned lại. Để tìm các model fine-tune này các bạn có thể truy cập các website sau.
Huggingface

Huggingface giống như github của model machine learning và AI. Huggingface lưu trữ và cho phép sử dụng thử các model machine learning được open-source. Một số link có thể hữu ích từ huggingface.
Stable Diffusion 2.0: https://huggingface.co/stabilityai/stable-diffusion-2
Stable Diffusion 1.4: https://huggingface.co/CompVis/stable-diffusion-v1-4
Civit-AI
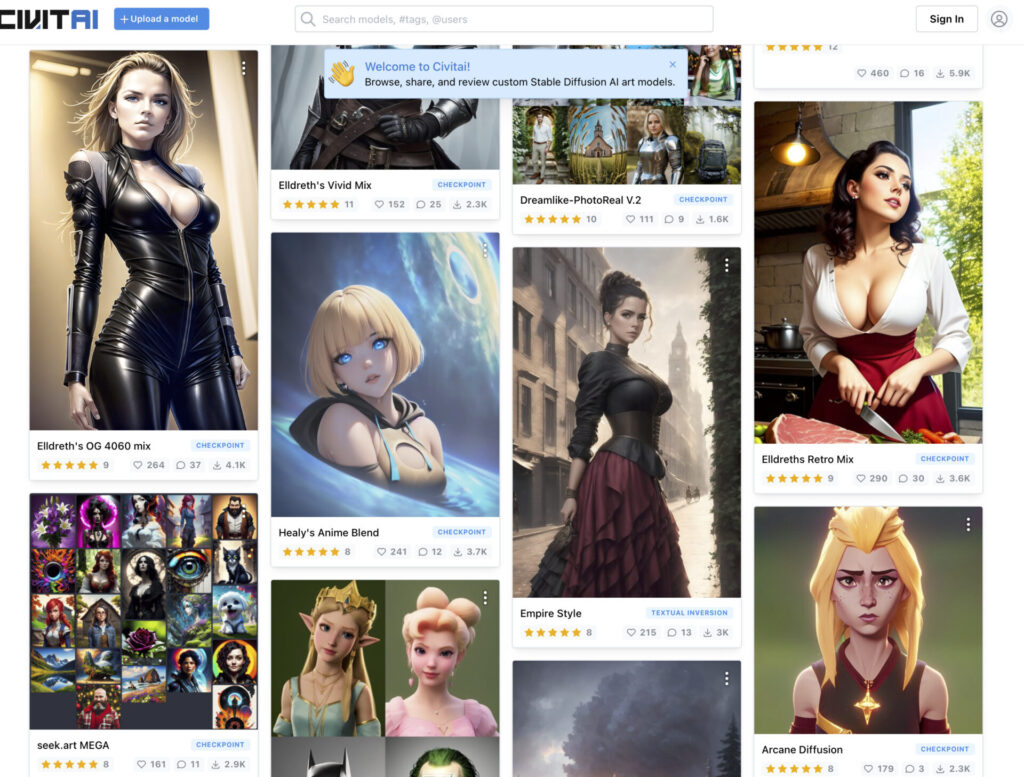
Có lẽ không cần nói nhiều các bạn cũng tự hình dung được trang web này có nhiều model đến mức nào khi nhìn vào trang chủ, hãy truy cập vào link này : https://civitai.com
Các vấn đề liên quan đến fine-tune
Ngoài việc tạo ảnh bạn hoàn toàn có thể sử dụng các công cụ trên để tạo model cho chính mình thông qua các phương thức dưới đây. Mình sẽ sử dụng Automatic1111 cho có tính thống nhất vì đây là cách phổ biến nhất.
Textual Inversion

Là cách can thiệp vào text embedding để tạo ra hình ảnh như mong muốn. Ví dụ bạn có thể train 1 cái textual inversion để khi nhập tên của bạn vào thì hình ảnh ra giống bạn vậy. Cách này chỉ đụng tới embedding layer.
Hướng dẫn tại đây https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
Dreambooth

Là cách train model theo một phương thức từ một bài báo nghiên cứu của Google tên là Dreambooth. Về mặt tính năng thì cũng khá tương tự Textual Inversion, tuy nhiên về bản chất cách can thiệp khác hoàn toàn textual inversion. Dreambooth sẽ can thiệp vào model U-net trực tiếp chứ không chỉ mỗi embedding layer.
Hướng dẫn tại đây https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
Hypernetwork
Một implementation rất lạ từ automatic1111, train một neural network bên ngoài model U Net sao đó chỉnh model này lại để nhận giá trị từ neural network bên ngoài, nhưng cũng có thể dùng để fine-tune được. Mình chưa có thời gian tìm hiểu về implementation này lắm, nhưng đại khái nó dùng tốt cho việc thay đổi style.
Hướng dẫn tại đây https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/2670
Instruct pix2pix (Updated)

Instruct pix2pix là phương pháp để biến đổi cách prompt lại gần giống với cách ra lệnh (nếu các bạn có dùng ChatGPT được built trên InstructGPT thì cái này cũng tương tự vậy).
ControlNet

ControlNet là một phương pháp để lưu trữ các tính chất ban đầu của hình ảnh trước khi cho Stable Diffusion. Nếu như sử dụng img2img thì hình ảnh có phần không ổn định (thay đổi rất random) thì với ControlNet hình ảnh luôn lưu trữ các tính chất ban dầu của hình gốc (như trên bạn có thể thấy con nai và bãi cỏ không hề bị biến dạng dù nhiều prompt khác nhau).
Mình sẽ bổ sung thêm phần giải thích về cơ chế hoạt động ControlNet sau, tuy nhiên có thể nói đây là một tính năng rất cách mạng vì nó có thể giúp việc làm animation trở nên dễ dàng hơn rất nhiều vì rào cản automation chủ yếu đến từ tính kém ổn định của output images của stable diffusion.
Giải thích thêm tại đây: https://the-decoder.com/controlnet-gives-you-more-control-over-stable-diffusions-creativi ty/.
Paper tại đây: https://arxiv.org/abs/2302.05543
LORA
Lora là một phương thức khác để fine-tune model mà không tác động trực tiếp tới weight chính (Unet) mà chỉ tác động tới cross attention layer.
LORA hiện nay là giải pháp được ưa thích nhất trong style transfer (đổi ảnh về style bạn muốn) và subject training (đưa chủ thế như một người nào đó vào hình ảnh). Lí do là vì LORA có độ chính xác rất cao về mức độ “thấu hiểu” style hoặc là subject. Ví dụ nếu bạn muốn hình ảnh của một diễn viên chẳng hạn, như Gal Gadot trong wonder woman. Tuy nhiên vì Gal Gadot quá nổi tiếng bởi vai diễn wonder woman nên mỗi lần bạn nhắc tới Gal Gadot thì sẽ dính và sót lại các feature của “wonder woman” như có khiên có vương miệng etc… Dùng LORA thì model sẽ hiểu được rằng bạn muốn nhắc tới là Gal Gadot và không bị dính các feature sót lại đó. Từ đó bạn có thể dễ dàng mix khái niệm Gal Gadot vào các feature khác.

Để có thể tự trãi nghiệm tính năng này các bạn hãy tìm hiểu trong các bài viết dưới đây.
Giải thích thêm về concept tại đây: https://replicate.com/blog/lora-faster-fine-tuning-of-stable-diffusion
Tutorial tại đây: https://www.youtube.com/watch?v=mfaqqL5yOO4
Các cộng đồng người dùng
Các bạn có thể lên các nơi này để thảo luận, chia sẻ, hoặc học hỏi thêm về stable diffusion
Reddit SD Sub (Official) – Cộng đồng lớn nhất: https://www.reddit.com/r/StableDiffusion/
Discord SD (Official) – Đây là Discord lớn nhất: https://discord.gg/stablediffusion
Các thuật ngữ thường dùng
Prompt: câu gợi ý
Negative prompt: là câu gợi ý của những thứ bạn không muốn thấy trong bức ảnh, nếu prompt là những thứ bạn muốn thấy thì negative prompt là toàn bộ những thứ ngược lại
Inpainting: là dùng AI để thay thế hoặc vẽ đè lên hình gốc như bức hình minh hoạ phía dưới

Outpainting: là dùng AI để vẽ nối thêm từ một ảnh gốc nhỏ, như minh hoạ phía dưới đang vẽ thêm một bãi cỏ cho con mèo.

Sẽ còn cập nhật thêm….
Các vấn đề học thuật/ lập trình
Có một số bạn sẽ không chỉ dừng lại ở việc dùng thử mà muốn tìm hiểu Stable Diffusion hoạt động như thế nào thì mình xin đưa ra một số nguồn tư liệu mình đã đọc qua dưới đây.
Stable Diffusion hoạt động như thế nào
Mình recommend các bạn xem Illustrated Stable Diffusion vì đây là bản hoàn chỉnh nhất, và giúp các bạn dễ hình như khái quát Stable Diffusion hoạt động như thế nào.
Illustrated Stable Diffusion (Bản hoàn chỉnh nhất): https://jalammar.github.io/illustrated-stable-diffusion/
Sau đó các bạn có thể xem tiếp Annotated Stable Diffusion tại đây sau khi đã hiểu khái quát về cấu trúc của Stable Diffusion.
Annotated Stable Diffusion: https://huggingface.co/blog/annotated-diffusion
Đây là cách mà mình cảm thấy là dễ tiếp cận nhất và không yêu cầu kiến thức ML sâu + đọc research paper gốc. Chỉ cần hiểu 2 bài này bạn hoàn toàn có thể commit code vào các repo open source như automatic1111,… hoặc viết các custom code để tạo ra thêm thay đổi cho stable diffusion. Tất nhiên là chỉ dừng lại ở mức ứng dụng. Ngoài ra không nên quên check github của SD: https://github.com/Stability-AI/stablediffusion
Fine-tune hoạt động như thế nào
Một số đường dẫn mà mình cảm thấy giải thích các phương pháp khá dễ hiểu (cá nhân mình hiểu được). Hiện tại có 2 phương pháp chính và được sử dụng nhiều là Textual Inversion và Dreambooth.
Ngoài ra còn có model merge, nhưng mình sẽ nói về chủ đề náy au.
Textual Inversion: https://huggingface.co/docs/diffusers/training/text_inversion
Dreambooth: https://dreambooth.github.io
Các thư viện liên quan
Pytorch

Stable Diffusion được implement tính tới thời điểm hiện tại chủ yếu bằng Pytorch, tất cả các model đang sử dụng Pytorch để load lại weight cho các model Stable Diffusion sau đó tạo ra ảnh. Các bạn có thể tìm hiểu thêm về Pytorch tại đây.
Pytorch: https://pytorch.org
Diffuser

Ngoài ra Huggingface còn có open source một thư viện khác tên là Diffuser, về cơ bản Diffuser là một wrapper của pytorch – không đúng lắm nhưng đại khái là vậy (một lớp cao hơn và không tương tác trực tiếp với pytorch). Bạn có thể sử dụng diffuser để tương tác với Stable Diffusion như một API mà không cần phải thông qua một web UI như automatic1111.
Tuy nhiên mình không khuyến khích lắm, vì sau thực tế sử dụng mình thấy diffuser đang lag behind automatic1111 khá nhiều về mặt tính năng và tính cập nhật của các implemenation.
Ngoài ra còn nhiều thứ viện liên quan tới tăng tốc và đồ hoạ mà mình không tiện nhắc tới ở đây (vì nó đính kèm vào các implementation phổ biến và sẽ có thể bị thay đổi trong tương lai)
Kết
Hiện tại mình chỉ đang cố gắng liệt kê một số thông tin mà các bạn có thể sử dụng để bắt đầu tìm hiểu về stable diffusion, mình sẽ update trên chính bài viết này về các chủ đề mở rộng hơn trong tương lai.